Load Packages
# numerical calculation & data frames
import numpy as np
import pandas as pd
# visualization
import matplotlib.pyplot as plt
import seaborn as sns
import seaborn.objects as so
# statistics
import statsmodels.api as smR for Data Science by Wickham & Grolemund
# numerical calculation & data frames
import numpy as np
import pandas as pd
# visualization
import matplotlib.pyplot as plt
import seaborn as sns
import seaborn.objects as so
# statistics
import statsmodels.api as sm# pandas options
pd.set_option("mode.copy_on_write", True)
pd.options.display.precision = 2
pd.options.display.float_format = '{:.2f}'.format # pd.reset_option('display.float_format')
pd.options.display.max_rows = 7
# Numpy options
np.set_printoptions(precision = 2, suppress=True)이번 장에서는 시각화를 하기 전후로, 중요한 데이터 패턴을 보기 위해서 새로운 변수를 만들거나 요약한 통계치를 만들 필요가 있는데 이를 다루는 핵심적인 함수들에 대해 익힙니다.
대략 다음과 같은 transform들을 조합하여 분석에 필요한 상태로 바꿉니다.
subsettingquery()sort_values()assign()groupby(), agg(), apply()On-time data for all flights that departed NYC (i.e. JFK, LGA or EWR) in 2013
# import the dataset
flights_data = sm.datasets.get_rdataset("flights", "nycflights13")
flights = flights_data.data
flights = flights.drop(columns="time_hour") # drop the "time_hour" column# Description
print(flights_data.__doc__)flights| year | month | day | dep_time | sched_dep_time | dep_delay | arr_time | sched_arr_time | arr_delay | carrier | flight | tailnum | origin | dest | air_time | distance | hour | minute | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2013 | 1 | 1 | 517.00 | 515 | 2.00 | 830.00 | 819 | 11.00 | UA | 1545 | N14228 | EWR | IAH | 227.00 | 1400 | 5 | 15 |
| 1 | 2013 | 1 | 1 | 533.00 | 529 | 4.00 | 850.00 | 830 | 20.00 | UA | 1714 | N24211 | LGA | IAH | 227.00 | 1416 | 5 | 29 |
| 2 | 2013 | 1 | 1 | 542.00 | 540 | 2.00 | 923.00 | 850 | 33.00 | AA | 1141 | N619AA | JFK | MIA | 160.00 | 1089 | 5 | 40 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 336773 | 2013 | 9 | 30 | NaN | 1210 | NaN | NaN | 1330 | NaN | MQ | 3461 | N535MQ | LGA | BNA | NaN | 764 | 12 | 10 |
| 336774 | 2013 | 9 | 30 | NaN | 1159 | NaN | NaN | 1344 | NaN | MQ | 3572 | N511MQ | LGA | CLE | NaN | 419 | 11 | 59 |
| 336775 | 2013 | 9 | 30 | NaN | 840 | NaN | NaN | 1020 | NaN | MQ | 3531 | N839MQ | LGA | RDU | NaN | 431 | 8 | 40 |
336776 rows × 18 columns
flights.info()<class 'pandas.core.frame.DataFrame'>
RangeIndex: 336776 entries, 0 to 336775
Data columns (total 18 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 year 336776 non-null int64
1 month 336776 non-null int64
2 day 336776 non-null int64
3 dep_time 328521 non-null float64
4 sched_dep_time 336776 non-null int64
5 dep_delay 328521 non-null float64
6 arr_time 328063 non-null float64
7 sched_arr_time 336776 non-null int64
8 arr_delay 327346 non-null float64
9 carrier 336776 non-null object
10 flight 336776 non-null int64
11 tailnum 334264 non-null object
12 origin 336776 non-null object
13 dest 336776 non-null object
14 air_time 327346 non-null float64
15 distance 336776 non-null int64
16 hour 336776 non-null int64
17 minute 336776 non-null int64
dtypes: float64(5), int64(9), object(4)
memory usage: 46.2+ MBquery()Conditional operators
>,>=,<,<=,
==(equal to),!=(not equal to)
&,and(and)
|,or(or)
~,not(not)
in(includes),not in(not included)
# Flights that arrived more than 120 minutes (two hours) late
flights.query('arr_delay > 120')| year | month | day | dep_time | sched_dep_time | dep_delay | arr_time | sched_arr_time | arr_delay | carrier | flight | tailnum | origin | dest | air_time | distance | hour | minute | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 119 | 2013 | 1 | 1 | 811.00 | 630 | 101.00 | 1047.00 | 830 | 137.00 | MQ | 4576 | N531MQ | LGA | CLT | 118.00 | 544 | 6 | 30 |
| 151 | 2013 | 1 | 1 | 848.00 | 1835 | 853.00 | 1001.00 | 1950 | 851.00 | MQ | 3944 | N942MQ | JFK | BWI | 41.00 | 184 | 18 | 35 |
| 218 | 2013 | 1 | 1 | 957.00 | 733 | 144.00 | 1056.00 | 853 | 123.00 | UA | 856 | N534UA | EWR | BOS | 37.00 | 200 | 7 | 33 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 336724 | 2013 | 9 | 30 | 2053.00 | 1815 | 158.00 | 2310.00 | 2054 | 136.00 | EV | 5292 | N600QX | EWR | ATL | 91.00 | 746 | 18 | 15 |
| 336757 | 2013 | 9 | 30 | 2159.00 | 1845 | 194.00 | 2344.00 | 2030 | 194.00 | 9E | 3320 | N906XJ | JFK | BUF | 50.00 | 301 | 18 | 45 |
| 336763 | 2013 | 9 | 30 | 2235.00 | 2001 | 154.00 | 59.00 | 2249 | 130.00 | B6 | 1083 | N804JB | JFK | MCO | 123.00 | 944 | 20 | 1 |
10034 rows × 18 columns
외부 변수/함수를 참조하려면 @와 함께
delay_cutoff = 120
flights.query('arr_delay > @delay_cutoff')def cut_off(df):
return df["dep_delay"].min()
flights.query('arr_delay < @cut_off(@flights)')위의 query 방식의 filtering은 다음과 같은 boolean indexing의 결과와 같음
flights[flights["arr_delay"] > 120]
# Flights that departed on January 1
flights.query('month == 1 & day == 1') # == 과 = 을 혼동하지 말것!| year | month | day | dep_time | sched_dep_time | dep_delay | arr_time | sched_arr_time | arr_delay | carrier | flight | tailnum | origin | dest | air_time | distance | hour | minute | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2013 | 1 | 1 | 517.00 | 515 | 2.00 | 830.00 | 819 | 11.00 | UA | 1545 | N14228 | EWR | IAH | 227.00 | 1400 | 5 | 15 |
| 1 | 2013 | 1 | 1 | 533.00 | 529 | 4.00 | 850.00 | 830 | 20.00 | UA | 1714 | N24211 | LGA | IAH | 227.00 | 1416 | 5 | 29 |
| 2 | 2013 | 1 | 1 | 542.00 | 540 | 2.00 | 923.00 | 850 | 33.00 | AA | 1141 | N619AA | JFK | MIA | 160.00 | 1089 | 5 | 40 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 839 | 2013 | 1 | 1 | NaN | 1935 | NaN | NaN | 2240 | NaN | AA | 791 | N3EHAA | LGA | DFW | NaN | 1389 | 19 | 35 |
| 840 | 2013 | 1 | 1 | NaN | 1500 | NaN | NaN | 1825 | NaN | AA | 1925 | N3EVAA | LGA | MIA | NaN | 1096 | 15 | 0 |
| 841 | 2013 | 1 | 1 | NaN | 600 | NaN | NaN | 901 | NaN | B6 | 125 | N618JB | JFK | FLL | NaN | 1069 | 6 | 0 |
842 rows × 18 columns
# Flights that departed in January or February
flights.query('month == 1 | month == 2')| year | month | day | dep_time | sched_dep_time | dep_delay | arr_time | sched_arr_time | arr_delay | carrier | flight | tailnum | origin | dest | air_time | distance | hour | minute | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2013 | 1 | 1 | 517.00 | 515 | 2.00 | 830.00 | 819 | 11.00 | UA | 1545 | N14228 | EWR | IAH | 227.00 | 1400 | 5 | 15 |
| 1 | 2013 | 1 | 1 | 533.00 | 529 | 4.00 | 850.00 | 830 | 20.00 | UA | 1714 | N24211 | LGA | IAH | 227.00 | 1416 | 5 | 29 |
| 2 | 2013 | 1 | 1 | 542.00 | 540 | 2.00 | 923.00 | 850 | 33.00 | AA | 1141 | N619AA | JFK | MIA | 160.00 | 1089 | 5 | 40 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 136244 | 2013 | 2 | 28 | NaN | 1115 | NaN | NaN | 1310 | NaN | MQ | 4485 | N725MQ | LGA | CMH | NaN | 479 | 11 | 15 |
| 136245 | 2013 | 2 | 28 | NaN | 830 | NaN | NaN | 1205 | NaN | UA | 1480 | NaN | EWR | SFO | NaN | 2565 | 8 | 30 |
| 136246 | 2013 | 2 | 28 | NaN | 840 | NaN | NaN | 1147 | NaN | UA | 443 | NaN | JFK | LAX | NaN | 2475 | 8 | 40 |
51955 rows × 18 columns
# A shorter way to select flights that departed in January or February
flights.query('month in [1, 2]')| year | month | day | dep_time | sched_dep_time | dep_delay | arr_time | sched_arr_time | arr_delay | carrier | flight | tailnum | origin | dest | air_time | distance | hour | minute | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2013 | 1 | 1 | 517.00 | 515 | 2.00 | 830.00 | 819 | 11.00 | UA | 1545 | N14228 | EWR | IAH | 227.00 | 1400 | 5 | 15 |
| 1 | 2013 | 1 | 1 | 533.00 | 529 | 4.00 | 850.00 | 830 | 20.00 | UA | 1714 | N24211 | LGA | IAH | 227.00 | 1416 | 5 | 29 |
| 2 | 2013 | 1 | 1 | 542.00 | 540 | 2.00 | 923.00 | 850 | 33.00 | AA | 1141 | N619AA | JFK | MIA | 160.00 | 1089 | 5 | 40 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 136244 | 2013 | 2 | 28 | NaN | 1115 | NaN | NaN | 1310 | NaN | MQ | 4485 | N725MQ | LGA | CMH | NaN | 479 | 11 | 15 |
| 136245 | 2013 | 2 | 28 | NaN | 830 | NaN | NaN | 1205 | NaN | UA | 1480 | NaN | EWR | SFO | NaN | 2565 | 8 | 30 |
| 136246 | 2013 | 2 | 28 | NaN | 840 | NaN | NaN | 1147 | NaN | UA | 443 | NaN | JFK | LAX | NaN | 2475 | 8 | 40 |
51955 rows × 18 columns
flights.query('arr_delay > 120 & ~(origin == "JFK")')| year | month | day | dep_time | sched_dep_time | dep_delay | arr_time | sched_arr_time | arr_delay | carrier | flight | tailnum | origin | dest | air_time | distance | hour | minute | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 119 | 2013 | 1 | 1 | 811.00 | 630 | 101.00 | 1047.00 | 830 | 137.00 | MQ | 4576 | N531MQ | LGA | CLT | 118.00 | 544 | 6 | 30 |
| 218 | 2013 | 1 | 1 | 957.00 | 733 | 144.00 | 1056.00 | 853 | 123.00 | UA | 856 | N534UA | EWR | BOS | 37.00 | 200 | 7 | 33 |
| 268 | 2013 | 1 | 1 | 1114.00 | 900 | 134.00 | 1447.00 | 1222 | 145.00 | UA | 1086 | N76502 | LGA | IAH | 248.00 | 1416 | 9 | 0 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 336529 | 2013 | 9 | 30 | 1738.00 | 1529 | 129.00 | 1906.00 | 1649 | 137.00 | EV | 4580 | N12563 | EWR | MKE | 110.00 | 725 | 15 | 29 |
| 336668 | 2013 | 9 | 30 | 1951.00 | 1649 | 182.00 | 2157.00 | 1903 | 174.00 | EV | 4294 | N13988 | EWR | SAV | 95.00 | 708 | 16 | 49 |
| 336724 | 2013 | 9 | 30 | 2053.00 | 1815 | 158.00 | 2310.00 | 2054 | 136.00 | EV | 5292 | N600QX | EWR | ATL | 91.00 | 746 | 18 | 15 |
6868 rows × 18 columns
flights.query('dep_time < sched_dep_time')| year | month | day | dep_time | sched_dep_time | dep_delay | arr_time | sched_arr_time | arr_delay | carrier | flight | tailnum | origin | dest | air_time | distance | hour | minute | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 3 | 2013 | 1 | 1 | 544.00 | 545 | -1.00 | 1004.00 | 1022 | -18.00 | B6 | 725 | N804JB | JFK | BQN | 183.00 | 1576 | 5 | 45 |
| 4 | 2013 | 1 | 1 | 554.00 | 600 | -6.00 | 812.00 | 837 | -25.00 | DL | 461 | N668DN | LGA | ATL | 116.00 | 762 | 6 | 0 |
| 5 | 2013 | 1 | 1 | 554.00 | 558 | -4.00 | 740.00 | 728 | 12.00 | UA | 1696 | N39463 | EWR | ORD | 150.00 | 719 | 5 | 58 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 336766 | 2013 | 9 | 30 | 2240.00 | 2250 | -10.00 | 2347.00 | 7 | -20.00 | B6 | 2002 | N281JB | JFK | BUF | 52.00 | 301 | 22 | 50 |
| 336767 | 2013 | 9 | 30 | 2241.00 | 2246 | -5.00 | 2345.00 | 1 | -16.00 | B6 | 486 | N346JB | JFK | ROC | 47.00 | 264 | 22 | 46 |
| 336769 | 2013 | 9 | 30 | 2349.00 | 2359 | -10.00 | 325.00 | 350 | -25.00 | B6 | 745 | N516JB | JFK | PSE | 196.00 | 1617 | 23 | 59 |
184782 rows × 18 columns
flights.query('arr_delay + dep_delay < 0')| year | month | day | dep_time | sched_dep_time | dep_delay | arr_time | sched_arr_time | arr_delay | carrier | flight | tailnum | origin | dest | air_time | distance | hour | minute | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 3 | 2013 | 1 | 1 | 544.00 | 545 | -1.00 | 1004.00 | 1022 | -18.00 | B6 | 725 | N804JB | JFK | BQN | 183.00 | 1576 | 5 | 45 |
| 4 | 2013 | 1 | 1 | 554.00 | 600 | -6.00 | 812.00 | 837 | -25.00 | DL | 461 | N668DN | LGA | ATL | 116.00 | 762 | 6 | 0 |
| 7 | 2013 | 1 | 1 | 557.00 | 600 | -3.00 | 709.00 | 723 | -14.00 | EV | 5708 | N829AS | LGA | IAD | 53.00 | 229 | 6 | 0 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 336766 | 2013 | 9 | 30 | 2240.00 | 2250 | -10.00 | 2347.00 | 7 | -20.00 | B6 | 2002 | N281JB | JFK | BUF | 52.00 | 301 | 22 | 50 |
| 336767 | 2013 | 9 | 30 | 2241.00 | 2246 | -5.00 | 2345.00 | 1 | -16.00 | B6 | 486 | N346JB | JFK | ROC | 47.00 | 264 | 22 | 46 |
| 336769 | 2013 | 9 | 30 | 2349.00 | 2359 | -10.00 | 325.00 | 350 | -25.00 | B6 | 745 | N516JB | JFK | PSE | 196.00 | 1617 | 23 | 59 |
188401 rows × 18 columns
flights.query('~dep_delay.isna() & arr_delay.isna()')| year | month | day | dep_time | sched_dep_time | dep_delay | arr_time | sched_arr_time | arr_delay | carrier | flight | tailnum | origin | dest | air_time | distance | hour | minute | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 471 | 2013 | 1 | 1 | 1525.00 | 1530 | -5.00 | 1934.00 | 1805 | NaN | MQ | 4525 | N719MQ | LGA | XNA | NaN | 1147 | 15 | 30 |
| 477 | 2013 | 1 | 1 | 1528.00 | 1459 | 29.00 | 2002.00 | 1647 | NaN | EV | 3806 | N17108 | EWR | STL | NaN | 872 | 14 | 59 |
| 615 | 2013 | 1 | 1 | 1740.00 | 1745 | -5.00 | 2158.00 | 2020 | NaN | MQ | 4413 | N739MQ | LGA | XNA | NaN | 1147 | 17 | 45 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 334495 | 2013 | 9 | 28 | 1214.00 | 1225 | -11.00 | 1801.00 | 1510 | NaN | AA | 300 | N488AA | EWR | DFW | NaN | 1372 | 12 | 25 |
| 335534 | 2013 | 9 | 29 | 1734.00 | 1711 | 23.00 | 2159.00 | 2020 | NaN | UA | 327 | N463UA | EWR | PDX | NaN | 2434 | 17 | 11 |
| 335805 | 2013 | 9 | 30 | 559.00 | 600 | -1.00 | NaN | 715 | NaN | WN | 464 | N411WN | EWR | MDW | NaN | 711 | 6 | 0 |
1175 rows × 18 columns
delay_time = 900
flights.query('arr_delay > @delay_time')| year | month | day | dep_time | sched_dep_time | dep_delay | arr_time | sched_arr_time | arr_delay | carrier | flight | tailnum | origin | dest | air_time | distance | hour | minute | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 7072 | 2013 | 1 | 9 | 641.00 | 900 | 1301.00 | 1242.00 | 1530 | 1272.00 | HA | 51 | N384HA | JFK | HNL | 640.00 | 4983 | 9 | 0 |
| 8239 | 2013 | 1 | 10 | 1121.00 | 1635 | 1126.00 | 1239.00 | 1810 | 1109.00 | MQ | 3695 | N517MQ | EWR | ORD | 111.00 | 719 | 16 | 35 |
| 151974 | 2013 | 3 | 17 | 2321.00 | 810 | 911.00 | 135.00 | 1020 | 915.00 | DL | 2119 | N927DA | LGA | MSP | 167.00 | 1020 | 8 | 10 |
| 173992 | 2013 | 4 | 10 | 1100.00 | 1900 | 960.00 | 1342.00 | 2211 | 931.00 | DL | 2391 | N959DL | JFK | TPA | 139.00 | 1005 | 19 | 0 |
| 235778 | 2013 | 6 | 15 | 1432.00 | 1935 | 1137.00 | 1607.00 | 2120 | 1127.00 | MQ | 3535 | N504MQ | JFK | CMH | 74.00 | 483 | 19 | 35 |
| 270376 | 2013 | 7 | 22 | 845.00 | 1600 | 1005.00 | 1044.00 | 1815 | 989.00 | MQ | 3075 | N665MQ | JFK | CVG | 96.00 | 589 | 16 | 0 |
| 327043 | 2013 | 9 | 20 | 1139.00 | 1845 | 1014.00 | 1457.00 | 2210 | 1007.00 | AA | 177 | N338AA | JFK | SFO | 354.00 | 2586 | 18 | 45 |
.query()의 결과는 view이므로 수정하려면 SettingWithCopyWarning; .copy() 후 사용 권장income total, income.totalquery() 조건의 참거짓에 상관없이 NA값은 모두 제외함
# df가 다음과 같을 때,
# A B
# 0 1.00 2.00
# 1 NaN 5.00
# 2 3.00 3.00
# 3 4.00 NaN
df.query('A > 1')
# A B
# 2 3.00 3.00
# 3 4.00 NaN
# NA를 포함하고자 할 때,
df.query('A > 1 | A.isna()') # .isna() : NA인지 여부
# A B
# 1 NaN 5.00
# 2 3.00 3.00
# 3 4.00 NaNNA(missing)에 대해서는 뒤에서 자세히
sort_values()# "year", "month", "day", "dep_time" 순서대로 내림차순으로 정렬
flights.sort_values(by=["year", "month", "day", "dep_time"], ascending=False) # default: ascending=True| year | month | day | dep_time | sched_dep_time | dep_delay | arr_time | sched_arr_time | arr_delay | carrier | flight | tailnum | origin | dest | air_time | distance | hour | minute | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 111279 | 2013 | 12 | 31 | 2356.00 | 2359 | -3.00 | 436.00 | 445 | -9.00 | B6 | 745 | N665JB | JFK | PSE | 200.00 | 1617 | 23 | 59 |
| 111278 | 2013 | 12 | 31 | 2355.00 | 2359 | -4.00 | 430.00 | 440 | -10.00 | B6 | 1503 | N509JB | JFK | SJU | 195.00 | 1598 | 23 | 59 |
| 111277 | 2013 | 12 | 31 | 2332.00 | 2245 | 47.00 | 58.00 | 3 | 55.00 | B6 | 486 | N334JB | JFK | ROC | 60.00 | 264 | 22 | 45 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 839 | 2013 | 1 | 1 | NaN | 1935 | NaN | NaN | 2240 | NaN | AA | 791 | N3EHAA | LGA | DFW | NaN | 1389 | 19 | 35 |
| 840 | 2013 | 1 | 1 | NaN | 1500 | NaN | NaN | 1825 | NaN | AA | 1925 | N3EVAA | LGA | MIA | NaN | 1096 | 15 | 0 |
| 841 | 2013 | 1 | 1 | NaN | 600 | NaN | NaN | 901 | NaN | B6 | 125 | N618JB | JFK | FLL | NaN | 1069 | 6 | 0 |
336776 rows × 18 columns
# "dep_time"은 내림차순으로, "arr_delay"는 오름차순으로
flights.sort_values(by=["dep_time", "arr_delay"], ascending=[False, True])| year | month | day | dep_time | sched_dep_time | dep_delay | arr_time | sched_arr_time | arr_delay | carrier | flight | tailnum | origin | dest | air_time | distance | hour | minute | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 150301 | 2013 | 3 | 15 | 2400.00 | 2359 | 1.00 | 324.00 | 338 | -14.00 | B6 | 727 | N636JB | JFK | BQN | 186.00 | 1576 | 23 | 59 |
| 87893 | 2013 | 12 | 5 | 2400.00 | 2359 | 1.00 | 427.00 | 440 | -13.00 | B6 | 1503 | N587JB | JFK | SJU | 182.00 | 1598 | 23 | 59 |
| 212941 | 2013 | 5 | 21 | 2400.00 | 2359 | 1.00 | 339.00 | 350 | -11.00 | B6 | 739 | N527JB | JFK | PSE | 199.00 | 1617 | 23 | 59 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 336773 | 2013 | 9 | 30 | NaN | 1210 | NaN | NaN | 1330 | NaN | MQ | 3461 | N535MQ | LGA | BNA | NaN | 764 | 12 | 10 |
| 336774 | 2013 | 9 | 30 | NaN | 1159 | NaN | NaN | 1344 | NaN | MQ | 3572 | N511MQ | LGA | CLE | NaN | 419 | 11 | 59 |
| 336775 | 2013 | 9 | 30 | NaN | 840 | NaN | NaN | 1020 | NaN | MQ | 3531 | N839MQ | LGA | RDU | NaN | 431 | 8 | 40 |
336776 rows × 18 columns
query()와 sort_values()을 함께 이용하여 좀 더 복잡한 문제를 해결할 수 있음
예를 들어, 다음과 같이 거의 제시간에 출발한(+- 10분) 항공편들 중 가장 도착 지연이 큰 항공편을 찾을 수 있음
(
flights
.query('dep_delay <= 10 & dep_delay >= -10')
.sort_values("arr_delay", ascending=False)
)| year | month | day | dep_time | sched_dep_time | dep_delay | arr_time | sched_arr_time | arr_delay | carrier | flight | tailnum | origin | dest | air_time | distance | hour | minute | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 55985 | 2013 | 11 | 1 | 658.00 | 700 | -2.00 | 1329.00 | 1015 | 194.00 | VX | 399 | N629VA | JFK | LAX | 336.00 | 2475 | 7 | 0 |
| 181270 | 2013 | 4 | 18 | 558.00 | 600 | -2.00 | 1149.00 | 850 | 179.00 | AA | 707 | N3EXAA | LGA | DFW | 234.00 | 1389 | 6 | 0 |
| 256340 | 2013 | 7 | 7 | 1659.00 | 1700 | -1.00 | 2050.00 | 1823 | 147.00 | US | 2183 | N948UW | LGA | DCA | 64.00 | 214 | 17 | 0 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 334354 | 2013 | 9 | 28 | 847.00 | 839 | 8.00 | 1130.00 | 959 | NaN | EV | 4510 | N14542 | EWR | MKE | NaN | 725 | 8 | 39 |
| 334412 | 2013 | 9 | 28 | 1010.00 | 1020 | -10.00 | 1344.00 | 1222 | NaN | EV | 4412 | N12175 | EWR | DSM | NaN | 1017 | 10 | 20 |
| 335805 | 2013 | 9 | 30 | 559.00 | 600 | -1.00 | NaN | 715 | NaN | WN | 464 | N411WN | EWR | MDW | NaN | 711 | 6 | 0 |
239109 rows × 18 columns
.sort_values(ignore_index=True)inplace=TrueNA는 sort 후 맨 뒤로na_position='first'unique()Series method
flights["origin"].unique() # return as a NumPy array, but depends on the dtypesarray(['EWR', 'LGA', 'JFK'], dtype=object)# finds all unique origin and destination pairs.
flights[["origin", "dest"]].value_counts() # default: dropna=Trueorigin dest
JFK LAX 11262
LGA ATL 10263
ORD 8857
...
LEX 1
JFK MEM 1
BHM 1
Length: 224, dtype: int64flights[["origin", "dest"]].value_counts().reset_index(name="n") origin dest n
0 JFK LAX 11262
1 LGA ATL 10263
2 LGA ORD 8857
.. ... ... ...
221 LGA LEX 1
222 JFK MEM 1
223 JFK BHM 1
[224 rows x 3 columns]기본적인 column selection은 이전 섹션 참고: subsetting
# Select columns by name
flights[["year", "month", "day"]] year month day
0 2013 1 1
1 2013 1 1
2 2013 1 1
... ... ... ...
336773 2013 9 30
336774 2013 9 30
336775 2013 9 30
[336776 rows x 3 columns]# Select all columns between year and day (inclusive)
flights.loc[:, "year":"day"] year month day
0 2013 1 1
1 2013 1 1
2 2013 1 1
... ... ... ...
336773 2013 9 30
336774 2013 9 30
336775 2013 9 30
[336776 rows x 3 columns]# Select all columns except those from year to day (inclusive)
# .isin(): includes
flights.loc[:, ~flights.columns.isin(["year", "month", "day"])] # Boolean indexing| dep_time | sched_dep_time | dep_delay | arr_time | sched_arr_time | arr_delay | carrier | flight | tailnum | origin | dest | air_time | distance | hour | minute | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 517.00 | 515 | 2.00 | 830.00 | 819 | 11.00 | UA | 1545 | N14228 | EWR | IAH | 227.00 | 1400 | 5 | 15 |
| 1 | 533.00 | 529 | 4.00 | 850.00 | 830 | 20.00 | UA | 1714 | N24211 | LGA | IAH | 227.00 | 1416 | 5 | 29 |
| 2 | 542.00 | 540 | 2.00 | 923.00 | 850 | 33.00 | AA | 1141 | N619AA | JFK | MIA | 160.00 | 1089 | 5 | 40 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 336773 | NaN | 1210 | NaN | NaN | 1330 | NaN | MQ | 3461 | N535MQ | LGA | BNA | NaN | 764 | 12 | 10 |
| 336774 | NaN | 1159 | NaN | NaN | 1344 | NaN | MQ | 3572 | N511MQ | LGA | CLE | NaN | 419 | 11 | 59 |
| 336775 | NaN | 840 | NaN | NaN | 1020 | NaN | MQ | 3531 | N839MQ | LGA | RDU | NaN | 431 | 8 | 40 |
336776 rows × 15 columns
Series/Index object의 method와 함께 (string method와는 구별)
.str.contains(), .str.startswith(), .str.endswith() ; True/False
# Select all columns that begin with “dep”.
flights.loc[:, flights.columns.str.startswith("dep")] # Boolean indexing dep_time dep_delay
0 517.00 2.00
1 533.00 4.00
2 542.00 2.00
... ... ...
336773 NaN NaN
336774 NaN NaN
336775 NaN NaN
[336776 rows x 2 columns]# Select all columns that are characters
flights.select_dtypes("object") # dtype: object, number, ... carrier tailnum origin dest
0 UA N14228 EWR IAH
1 UA N24211 LGA IAH
2 AA N619AA JFK MIA
... ... ... ... ...
336773 MQ N535MQ LGA BNA
336774 MQ N511MQ LGA CLE
336775 MQ N839MQ LGA RDU
[336776 rows x 4 columns]index selection: reindex
rename()flights.rename(
columns={"dep_time": "dep_t", "arr_time": "arr_t"}, # default: index=
# inplace=True # dataframe is updated
)| year | month | day | dep_t | sched_dep_time | dep_delay | arr_t | sched_arr_time | arr_delay | carrier | flight | tailnum | origin | dest | air_time | distance | hour | minute | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2013 | 1 | 1 | 517.00 | 515 | 2.00 | 830.00 | 819 | 11.00 | UA | 1545 | N14228 | EWR | IAH | 227.00 | 1400 | 5 | 15 |
| 1 | 2013 | 1 | 1 | 533.00 | 529 | 4.00 | 850.00 | 830 | 20.00 | UA | 1714 | N24211 | LGA | IAH | 227.00 | 1416 | 5 | 29 |
| 2 | 2013 | 1 | 1 | 542.00 | 540 | 2.00 | 923.00 | 850 | 33.00 | AA | 1141 | N619AA | JFK | MIA | 160.00 | 1089 | 5 | 40 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 336773 | 2013 | 9 | 30 | NaN | 1210 | NaN | NaN | 1330 | NaN | MQ | 3461 | N535MQ | LGA | BNA | NaN | 764 | 12 | 10 |
| 336774 | 2013 | 9 | 30 | NaN | 1159 | NaN | NaN | 1344 | NaN | MQ | 3572 | N511MQ | LGA | CLE | NaN | 419 | 11 | 59 |
| 336775 | 2013 | 9 | 30 | NaN | 840 | NaN | NaN | 1020 | NaN | MQ | 3531 | N839MQ | LGA | RDU | NaN | 431 | 8 | 40 |
336776 rows × 18 columns
Series의 경우
s = flights.dep_delay.head(3)
# 0 2.00
# 1 4.00
# 2 2.00
# Name: dep_delay, dtype: float64
s.rename("what")
# 0 2.00
# 1 4.00
# 2 2.00
# Name: what, dtype: float64함수 str.capitalize, str.lower, str.upper과 함께
flights.rename(str.capitalize, axis="columns").head(3) # axis=1| Year | Month | Day | Dep_time | Sched_dep_time | Dep_delay | Arr_time | Sched_arr_time | Arr_delay | Carrier | Flight | Tailnum | Origin | Dest | Air_time | Distance | Hour | Minute | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2013 | 1 | 1 | 517.00 | 515 | 2.00 | 830.00 | 819 | 11.00 | UA | 1545 | N14228 | EWR | IAH | 227.00 | 1400 | 5 | 15 |
| 1 | 2013 | 1 | 1 | 533.00 | 529 | 4.00 | 850.00 | 830 | 20.00 | UA | 1714 | N24211 | LGA | IAH | 227.00 | 1416 | 5 | 29 |
| 2 | 2013 | 1 | 1 | 542.00 | 540 | 2.00 | 923.00 | 850 | 33.00 | AA | 1141 | N619AA | JFK | MIA | 160.00 | 1089 | 5 | 40 |
index를 rename할 수도 있음
flights.rename(
index={0: "a", 1: "b"},
).head(3)
# year month day dep_time ...
# a 2013 1 1 517.00 ...
# b 2013 1 1 533.00 ...
# 2 2013 1 1 542.00 ...assign()cols = ["year", "month", "day", "distance", "air_time"] + \
[col for col in flights.columns if col.endswith("delay")] # string method .endswith
flights_sml = flights[cols].copy()
flights_sml year month day distance air_time dep_delay arr_delay
0 2013 1 1 1400 227.00 2.00 11.00
1 2013 1 1 1416 227.00 4.00 20.00
2 2013 1 1 1089 160.00 2.00 33.00
... ... ... ... ... ... ... ...
336773 2013 9 30 764 NaN NaN NaN
336774 2013 9 30 419 NaN NaN NaN
336775 2013 9 30 431 NaN NaN NaN
[336776 rows x 7 columns]# 새로 만들어진 변수는 맨 뒤로
flights_sml.assign(
gain=lambda x: x.dep_delay - x.arr_delay, # x: DataFrame, flights_sml
speed=flights_sml["distance"] / flights_sml["air_time"] * 60 # 직접 DataFrame 참조할 수도 있음
) year month day distance air_time dep_delay arr_delay gain \
0 2013 1 1 1400 227.00 2.00 11.00 -9.00
1 2013 1 1 1416 227.00 4.00 20.00 -16.00
2 2013 1 1 1089 160.00 2.00 33.00 -31.00
... ... ... ... ... ... ... ... ...
336773 2013 9 30 764 NaN NaN NaN NaN
336774 2013 9 30 419 NaN NaN NaN NaN
336775 2013 9 30 431 NaN NaN NaN NaN
speed
0 370.04
1 374.27
2 408.38
... ...
336773 NaN
336774 NaN
336775 NaN
[336776 rows x 9 columns]# 앞에서 만든 변수나 함수를 이용할 수 있음
flights_sml.assign(
gain=lambda x: x.dep_delay - x.arr_delay,
hours=lambda x: x.air_time / 60,
gain_per_hour=lambda x: x.gain / x.hours,
rounded=lambda x: np.round(x.gain_per_hour, 1) # use a numpy function
) year month day distance air_time dep_delay arr_delay gain \
0 2013 1 1 1400 227.00 2.00 11.00 -9.00
1 2013 1 1 1416 227.00 4.00 20.00 -16.00
2 2013 1 1 1089 160.00 2.00 33.00 -31.00
... ... ... ... ... ... ... ... ...
336773 2013 9 30 764 NaN NaN NaN NaN
336774 2013 9 30 419 NaN NaN NaN NaN
336775 2013 9 30 431 NaN NaN NaN NaN
hours gain_per_hour rounded
0 3.78 -2.38 -2.40
1 3.78 -4.23 -4.20
2 2.67 -11.62 -11.60
... ... ... ...
336773 NaN NaN NaN
336774 NaN NaN NaN
336775 NaN NaN NaN
[336776 rows x 11 columns]# Find the fastest flights
(
flights_sml
.assign(speed=lambda x: x.distance / x.air_time)
.sort_values(by="speed", ascending=False)
.head(5)
) year month day distance air_time dep_delay arr_delay speed
216447 2013 5 25 762 65.00 9.00 -14.00 11.72
251999 2013 7 2 1008 93.00 45.00 26.00 10.84
205388 2013 5 13 594 55.00 15.00 -1.00 10.80
157516 2013 3 23 748 70.00 4.00 2.00 10.69
10223 2013 1 12 1035 105.00 -1.00 -28.00 9.86groupby()groupby()는 데이터를 의미있는 그룹으로 나누어 분석할 수 있도록 해줌.count(), .sum(), .mean(), .min(), .max()과 같은 통계치를 구하는 methods와 함께 효과적으로, 자주 활용됨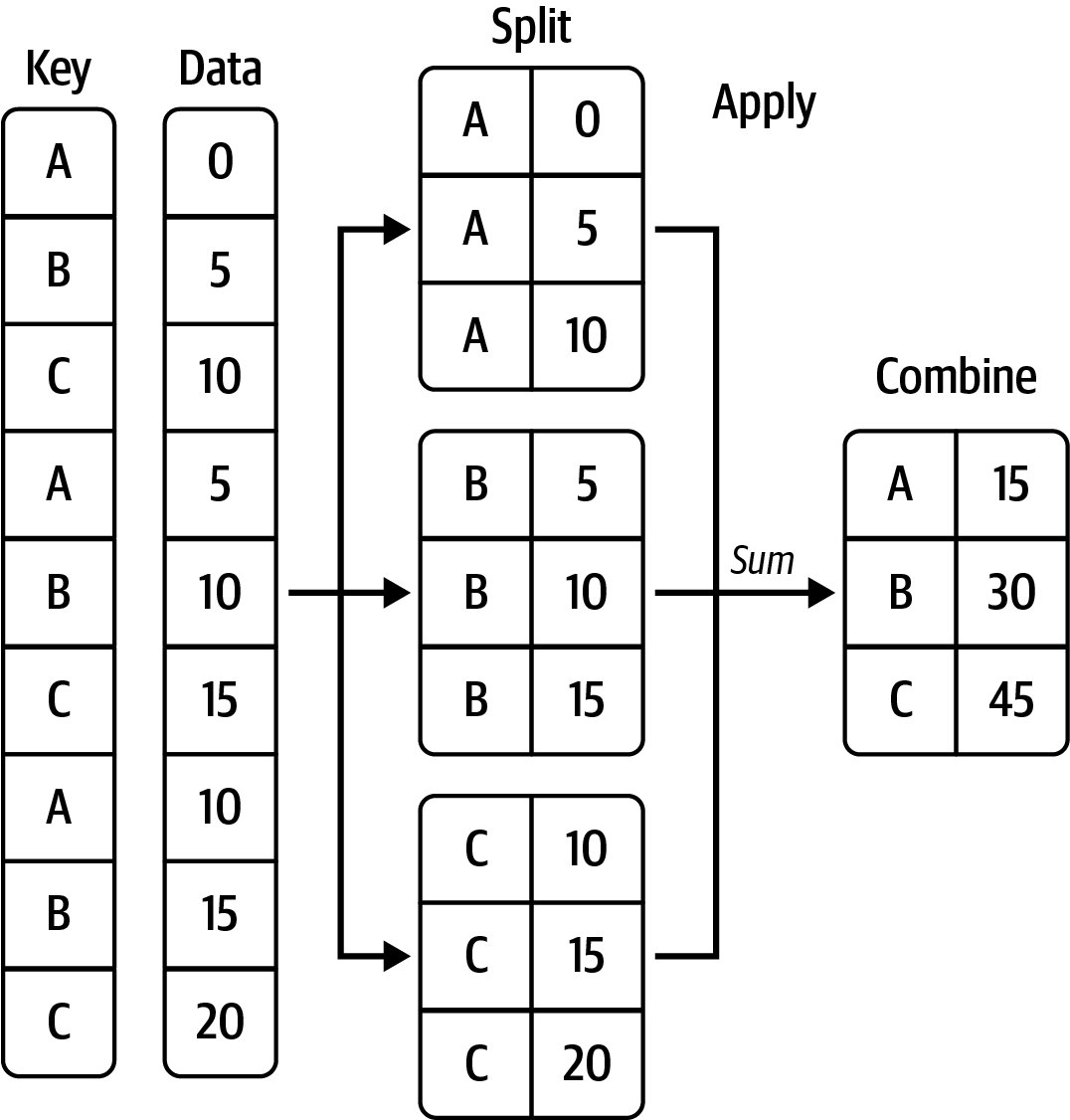
Source: Ch.10 in Python for Data Analysis (3e) by Wes McKinney
아래 표는 groupby()와 함께 자주 쓰이는 효율적인 methods
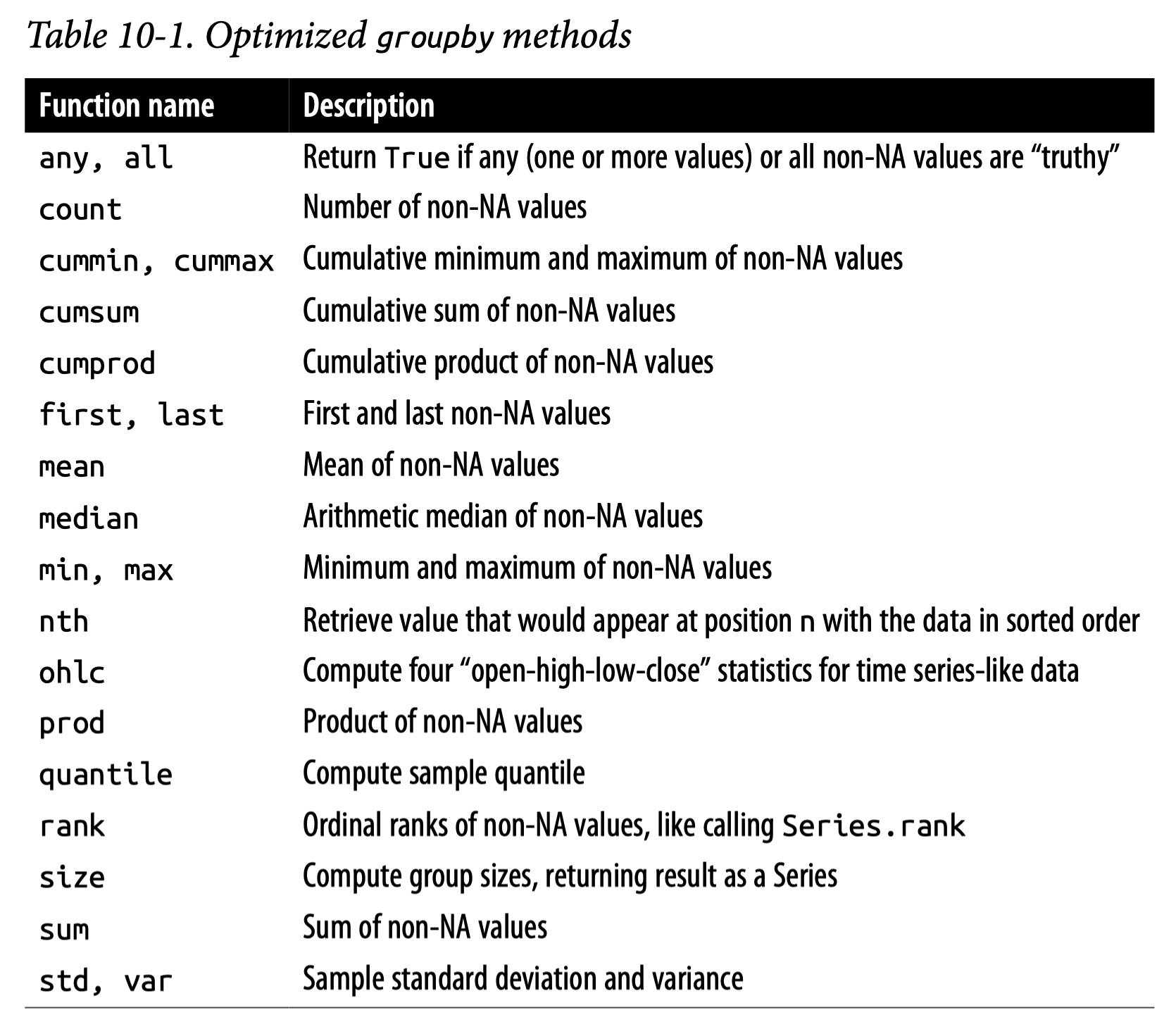
Source: Ch.10 in Python for Data Analysis (3e) by Wes McKinney
flights.groupby("month") # “GroupBy” object<pandas.core.groupby.generic.DataFrameGroupBy object at 0x28001c810>flights_sml.groupby("month").mean() year day distance air_time dep_delay arr_delay
month
1 2013.00 15.99 1006.84 154.19 10.04 6.13
2 2013.00 14.74 1000.98 151.35 10.82 5.61
3 2013.00 16.00 1011.99 149.08 13.23 5.81
... ... ... ... ... ... ...
10 2013.00 15.98 1038.88 148.89 6.24 -0.17
11 2013.00 15.29 1050.31 155.47 5.44 0.46
12 2013.00 15.72 1064.66 162.59 16.58 14.87
[12 rows x 6 columns]# 보통은 다음과 같이 특정 columns을 선택
flights.groupby("month")["dep_delay"] # [["dep_delay"]] 처럼 list로 입력하면 DataFrameGroupBy object<pandas.core.groupby.generic.SeriesGroupBy object at 0x13d0126d0>flights.groupby("month")["dep_delay"].mean() # Series GroupBy object에 적용된 결과는 Seriesmonth
1 10.04
2 10.82
3 13.23
...
10 6.24
11 5.44
12 16.58
Name: dep_delay, Length: 12, dtype: float64flights.groupby("month")[["dep_delay", "arr_delay"]].mean().head(3) dep_delay arr_delay
month
1 10.04 6.13
2 10.82 5.61
3 13.23 5.81# 2 levels의 grouping
flights.groupby(["month", "day"])["arr_delay"].nsmallest(1)month day
1 1 696 -48.00
2 919 -59.00
3 2035 -65.00
...
12 29 108914 -60.00
30 110330 -45.00
31 111113 -44.00
Name: arr_delay, Length: 365, dtype: float64Multi-index의 level을 drop하려면 droplevel()
flights.groupby(["month", "day"])["arr_delay"].nsmallest(1).droplevel(2)
# month day
# 1 1 -48.00
# 2 -59.00
# 3 -65.00
# ...
# 12 29 -60.00
# 30 -45.00
# 31 -44.00
# Name: arr_delay, Length: 365, dtype: float64flights.groupby(["origin", "dest"])["arr_delay"].count()origin dest
EWR ALB 418
ANC 8
ATL 4876
...
LGA TVC 73
TYS 265
XNA 709
Name: arr_delay, Length: 224, dtype: int64as_index=False: grouping 변수들을 index가 아닌 columns으로
flights.groupby(["month", "day"], as_index=False)["arr_delay"].mean().head(3)
# month day arr_delay
# 0 1 1 12.65
# 1 1 2 12.69
# 2 1 3 5.73물론, 결과물에 .reset_index() method를 사용해도 됨
원칙적으로 grouping은 같은 DataFrame의 변수일 필요없이 match만 되면 됨
Source: Wes McKinney’s
# df
# key1 key2 data1 data2
# 0 a 1 0.36 -0.42
# 1 a 2 -1.51 0.04
# 2 None 1 0.75 -0.28
# 3 b 2 0.57 0.25
# 4 b 1 1.30 -0.77
# 5 a <NA> -0.53 -0.73
# 6 None 1 2.04 -0.37
states = np.array(["OH", "CA", "CA", "OH", "OH", "CA", "OH"])
years = [2005, 2005, 2006, 2005, 2006, 2005, 2006]
df["data1"].groupby([states, years]).mean()
# CA 2005 -1.02
# 2006 0.75
# OH 2005 0.46
# 2006 1.67
# Name: data1, dtype: float64flights.groupby("dest").size() # .size(): group의 사이즈/열의 갯수dest
ABQ 254
ACK 265
ALB 439
...
TVC 101
TYS 631
XNA 1036
Length: 105, dtype: int64flights.groupby("tailnum", dropna=False).size() # groupby는 기본적으로 NA 무시tailnum
D942DN 4
N0EGMQ 371
N10156 153
...
N999DN 61
N9EAMQ 248
NaN 2512
Length: 4044, dtype: int64.size()는 .value_counts()와 유사하게 사용될 수 있음
flights["tailnum"].value_counts(dropna=False)
# NaN 2512
# N725MQ 575
# N722MQ 513
# ...
# N318AS 1
# N651UA 1
# N557AS 1
# Name: tailnum, Length: 4044, dtype: int64Index에 grouping하는 방식에 대해서는 Wes McKineey’s Chapter 10 참고
Time series 데이터의 경우 다양한 grouping 방식이 존재
Stephanie Molin의 ch.4 Working with time series data 참고
예를 들어, facebook stock에 대한 자료에서 2018년 4분기에 해당하는 날을 week단위로 그룹핑하여 volume을 다음과 같이 계산할 수 있음
fb.loc['2018-Q4'].groupby(pd.Grouper(freq='W')).volume.sum()groupby filtering
flights.groupby(["year", "month", "day"]).filter(lambda x: x["arr_delay"].mean() < 0)agg()Aggregations: data transformation that produces scalar values from arrays
앞서 GroupBy object에 직접 stats function을 적용하였는데, agg()를 이용하여 더 확장, 일반화할 수 있음
# 모두 동일
flights_sml.groupby("month").mean()
flights_sml.groupby("month").agg("mean") # function names
flights_sml.groupby("month").agg(np.mean) # general functions year day distance air_time dep_delay arr_delay
month
1 2013.00 15.99 1006.84 154.19 10.04 6.13
2 2013.00 14.74 1000.98 151.35 10.82 5.61
3 2013.00 16.00 1011.99 149.08 13.23 5.81
... ... ... ... ... ... ...
10 2013.00 15.98 1038.88 148.89 6.24 -0.17
11 2013.00 15.29 1050.31 155.47 5.44 0.46
12 2013.00 15.72 1064.66 162.59 16.58 14.87
[12 rows x 6 columns]차이 참고
flights_sml.groupby("month")["arr_delay"].agg(["mean"])
flights_sml.groupby("month")[["arr_delay"]].agg("mean")flights.groupby("month")["dep_delay"].agg(["mean", "count"]) mean count
month
1 10.04 26483
2 10.82 23690
3 13.23 27973
... ... ...
10 6.24 28653
11 5.44 27035
12 16.58 27110
[12 rows x 2 columns]flights_sml.groupby("month")[["arr_delay", "dep_delay"]].agg(["mean", "count"]) arr_delay dep_delay
mean count mean count
month
1 6.13 26398 10.04 26483
2 5.61 23611 10.82 23690
3 5.81 27902 13.23 27973
... ... ... ... ...
10 -0.17 28618 6.24 28653
11 0.46 26971 5.44 27035
12 14.87 27020 16.58 27110
[12 rows x 4 columns]# Apply different funtions to different columns
flights_agg = flights.groupby("month").agg({
"air_time": ["min", "max"],
"dep_delay": "mean",
"arr_delay": "median"
})
flights_agg.head(3) air_time dep_delay arr_delay
min max mean median
month
1 20.00 667.00 10.04 -3.00
2 21.00 691.00 10.82 -3.00
3 21.00 695.00 13.23 -6.00MultiIndex를 collapse하는 팁
flights_agg.columns
# MultiIndex([( 'air_time', 'min'),
# ( 'air_time', 'max'),
# ('dep_delay', 'mean'),
# ('arr_delay', 'median')],
# )
flights_agg.columns = ['_'.join(col_agg) for col_agg in flights_agg.columns]
flights_agg.head(3)
# air_time_min air_time_max dep_delay_mean arr_delay_median
# month
# 1 20.00 667.00 10.04 -3.00
# 2 21.00 691.00 10.82 -3.00
# 3 21.00 695.00 13.23 -6.00agg()에는 custom function을 pass할 수 있음
단, the optimized functions (Table 10-1)에 비해 일반적으로 훨씬 느림
def peak_to_peak(arr):
return arr.max() - arr.min()grouped = flights_sml.groupby(["month", "day"])
grouped_dist = flights_sml.groupby(["month", "day"])["distance"]
grouped_dist.agg(["std", peak_to_peak]) # a list of functions std peak_to_peak
month day
1 1 727.73 4889
2 721.72 4889
3 714.95 4903
... ... ...
12 29 728.78 4887
30 723.88 4887
31 731.36 4887
[365 rows x 2 columns]# Naming a function as a tuple
grouped_dist.agg([("sd", "std"), ("range", peak_to_peak)]) sd range
month day
1 1 727.73 4889
2 721.72 4889
3 714.95 4903
... ... ...
12 29 728.78 4887
30 723.88 4887
31 731.36 4887
[365 rows x 2 columns].describe()는 aggregation은 아니나 grouped objects에 적용가능
grouped[["dep_delay", "arr_delay"]].describe()
# dep_delay arr_delay \
# count mean std min 25% 50% 75% max count mean
# month
# 1 26483.00 10.04 36.39 -30.00 -5.00 -2.00 8.00 1301.00 26398.00 6.13
# 2 23690.00 10.82 36.27 -33.00 -5.00 -2.00 9.00 853.00 23611.00 5.61
# 3 27973.00 13.23 40.13 -25.00 -5.00 -1.00 12.00 911.00 27902.00 5.81
# ... ... ... ... ... ... ... ... ... ... ...
# std min 25% 50% 75% max
# month
# 1 40.42 -70.00 -15.00 -3.00 13.00 1272.00
# 2 39.53 -70.00 -15.00 -3.00 13.00 834.00
# 3 44.12 -68.00 -18.00 -6.00 13.00 915.00
# ... ... ... ... ... ... ...
# [12 rows x 16 columns]transform()앞서 group별로 통계치가 summary되어 원래 reduced 데이터를 변형됐다면,
transform()은 group별로 얻은 통계치가 원래 데이터의 형태를 그대로 보존하면서 출력
만약, 전달되는 함수가 Series를 반환하려면, 동일한 사이즈로 반환되어야 함.
flights_sml.groupby(["month"])["arr_delay"].mean()month
1 6.13
2 5.61
3 5.81
...
10 -0.17
11 0.46
12 14.87
Name: arr_delay, Length: 12, dtype: float64grouped_delay = flights_sml.groupby(["month"])["arr_delay"].transform("mean")
grouped_delay0 6.13
1 6.13
2 6.13
...
336773 -4.02
336774 -4.02
336775 -4.02
Name: arr_delay, Length: 336776, dtype: float64flights_sml["monthly_delay"] = grouped_delay
flights_sml year month day distance air_time dep_delay arr_delay \
0 2013 1 1 1400 227.00 2.00 11.00
1 2013 1 1 1416 227.00 4.00 20.00
2 2013 1 1 1089 160.00 2.00 33.00
... ... ... ... ... ... ... ...
336773 2013 9 30 764 NaN NaN NaN
336774 2013 9 30 419 NaN NaN NaN
336775 2013 9 30 431 NaN NaN NaN
monthly_delay
0 6.13
1 6.13
2 6.13
... ...
336773 -4.02
336774 -4.02
336775 -4.02
[336776 rows x 8 columns]Q: 1년에 10000편 이상 운항편이 있는 도착지로 가는 항공편들만 추리면,
dest_size = flights.groupby("dest").transform("size")
dest_size
# 또는 flights.groupby("dest")["dest"].transform("count")0 7198
1 7198
2 11728
...
336773 6333
336774 4573
336775 8163
Length: 336776, dtype: int64# 1년에 10000편 이상 운항편이 있는 도착지에 대한 항공편
flights[dest_size > 10000] year month day dep_time sched_dep_time dep_delay arr_time \
2 2013 1 1 542.00 540 2.00 923.00
4 2013 1 1 554.00 600 -6.00 812.00
5 2013 1 1 554.00 558 -4.00 740.00
... ... ... ... ... ... ... ...
336762 2013 9 30 2233.00 2113 80.00 112.00
336763 2013 9 30 2235.00 2001 154.00 59.00
336768 2013 9 30 2307.00 2255 12.00 2359.00
sched_arr_time arr_delay carrier flight tailnum origin dest \
2 850 33.00 AA 1141 N619AA JFK MIA
4 837 -25.00 DL 461 N668DN LGA ATL
5 728 12.00 UA 1696 N39463 EWR ORD
... ... ... ... ... ... ... ...
336762 30 42.00 UA 471 N578UA EWR SFO
336763 2249 130.00 B6 1083 N804JB JFK MCO
336768 2358 1.00 B6 718 N565JB JFK BOS
air_time distance hour minute
2 160.00 1089 5 40
4 116.00 762 6 0
5 150.00 719 5 58
... ... ... ... ...
336762 318.00 2565 21 13
336763 123.00 944 20 1
336768 33.00 187 22 55
[131440 rows x 18 columns]Q: 하루 중 출발 지연이 가장 늦은 두 항공편들을 매일 각각 구하면,
def get_ranks(group):
return group.rank(ascending=False, method="min") # method: 동일 등수에 대한 처리방식
delay_rank = flights.groupby(["month", "day"])["dep_delay"].transform(get_ranks)
# 또는 .transform("rank", ascending=False, method="min")
delay_rank0 302.00
1 269.00
2 302.00
...
336773 NaN
336774 NaN
336775 NaN
Name: dep_delay, Length: 336776, dtype: float64flights[delay_rank < 3].head(6) year month day dep_time sched_dep_time dep_delay arr_time \
151 2013 1 1 848.00 1835 853.00 1001.00
834 2013 1 1 2343.00 1724 379.00 314.00
1440 2013 1 2 1607.00 1030 337.00 2003.00
1749 2013 1 2 2131.00 1512 379.00 2340.00
2598 2013 1 3 2008.00 1540 268.00 2339.00
2637 2013 1 3 2056.00 1605 291.00 2239.00
sched_arr_time arr_delay carrier flight tailnum origin dest air_time \
151 1950 851.00 MQ 3944 N942MQ JFK BWI 41.00
834 1938 456.00 EV 4321 N21197 EWR MCI 222.00
1440 1355 368.00 AA 179 N324AA JFK SFO 346.00
1749 1741 359.00 UA 488 N593UA LGA DEN 228.00
2598 1909 270.00 DL 2027 N338NW JFK FLL 158.00
2637 1754 285.00 9E 3459 N928XJ JFK BNA 125.00
distance hour minute
151 184 18 35
834 1092 17 24
1440 2586 10 30
1749 1620 15 12
2598 1069 15 40
2637 765 16 5 Q: Normalize air time by destination
dest_air = flights.groupby("dest")["air_time"]# Z = (x - mean) / std
(flights['air_time'] - dest_air.transform('mean')) / dest_air.transform('std')0 1.73
1 1.73
2 0.61
...
336773 NaN
336774 NaN
336775 NaN
Name: air_time, Length: 336776, dtype: float64def normalize(x):
return (x - x.mean()) / x.std()dest_air.transform(normalize)0 1.73
1 1.73
2 0.61
...
336773 NaN
336774 NaN
336775 NaN
Name: air_time, Length: 336776, dtype: float64apply()Apply: General split-apply-combine in McKineey’s Chapter 10.3 참고
The most general-purpose GroupBy method is apply, which is the subject of this section. apply splits the object being manipulated into pieces, invokes the passed function on each piece, and then attempts to concatenate the pieces.
tips = sns.load_dataset("tips")
tips = tips.assign(tip_pct = lambda x: x.tip / x.total_bill)
tips.head(3) total_bill tip sex smoker day time size tip_pct
0 16.99 1.01 Female No Sun Dinner 2 0.06
1 10.34 1.66 Male No Sun Dinner 3 0.16
2 21.01 3.50 Male No Sun Dinner 3 0.17def top(df, n=5, column="tip_pct"):
return df.sort_values(column, ascending=False)[:n]top(tips, n=4) total_bill tip sex smoker day time size tip_pct
172 7.25 5.15 Male Yes Sun Dinner 2 0.71
178 9.60 4.00 Female Yes Sun Dinner 2 0.42
67 3.07 1.00 Female Yes Sat Dinner 1 0.33
232 11.61 3.39 Male No Sat Dinner 2 0.29tips.groupby("time").apply(top) total_bill tip sex smoker day time size tip_pct
time
Lunch 149 7.51 2.00 Male No Thur Lunch 2 0.27
221 13.42 3.48 Female Yes Fri Lunch 2 0.26
194 16.58 4.00 Male Yes Thur Lunch 2 0.24
... ... ... ... ... ... ... ... ...
Dinner 67 3.07 1.00 Female Yes Sat Dinner 1 0.33
232 11.61 3.39 Male No Sat Dinner 2 0.29
183 23.17 6.50 Male Yes Sun Dinner 4 0.28
[10 rows x 8 columns]tips.groupby(["time", "day"]).apply(top, n=1, column="total_bill") total_bill tip sex smoker day time size tip_pct
time day
Lunch Thur 197 43.11 5.00 Female Yes Thur Lunch 4 0.12
Fri 225 16.27 2.50 Female Yes Fri Lunch 2 0.15
Dinner Thur 243 18.78 3.00 Female No Thur Dinner 2 0.16
Fri 95 40.17 4.73 Male Yes Fri Dinner 4 0.12
Sat 170 50.81 10.00 Male Yes Sat Dinner 3 0.20
Sun 156 48.17 5.00 Male No Sun Dinner 6 0.10What occurs inside the function passed is up to you;
it must either return a pandas object or a scalar value.
tips.groupby("sex")["tip_pct"].describe() count mean std min 25% 50% 75% max
sex
Male 157.00 0.16 0.06 0.04 0.12 0.15 0.19 0.71
Female 87.00 0.17 0.05 0.06 0.14 0.16 0.19 0.42Inside GroupBy, when you invoke a method like describe, it is actually just a shortcut for:
def f(group):
return group.describe()Suppressing the Group Keys
tips.groupby("time", group_keys=False).apply(top)
# total_bill tip sex smoker day time size tip_pct
# 149 7.51 2.00 Male No Thur Lunch 2 0.27
# 221 13.42 3.48 Female Yes Fri Lunch 2 0.26
# 194 16.58 4.00 Male Yes Thur Lunch 2 0.24
# 88 24.71 5.85 Male No Thur Lunch 2 0.24
# 222 8.58 1.92 Male Yes Fri Lunch 1 0.22
# 172 7.25 5.15 Male Yes Sun Dinner 2 0.71
# 178 9.60 4.00 Female Yes Sun Dinner 2 0.42
# 67 3.07 1.00 Female Yes Sat Dinner 1 0.33
# 232 11.61 3.39 Male No Sat Dinner 2 0.29
# 183 23.17 6.50 Male Yes Sun Dinner 4 0.28비교
applymap: element-wise, DataFrame methodmap: element-wise, Series methodapply: column/row-wise, DataFrame method, 또는 element-wise, Series method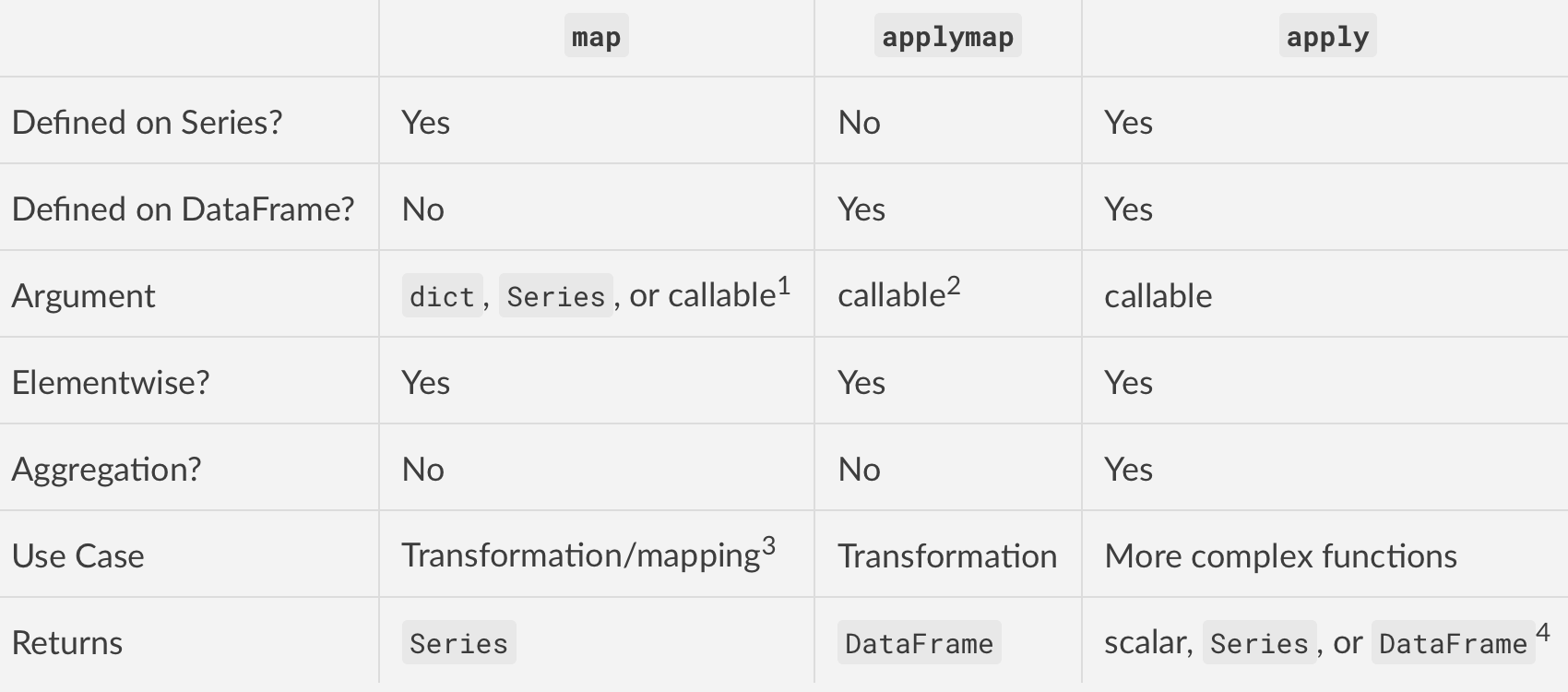
def my_format(x):
return f"{x:.1f}"tips_num = tips.select_dtypes("number")# element-wise, DataFrame method
tips_num.applymap(my_format) total_bill tip size tip_pct
0 17.0 1.0 2.0 0.1
1 10.3 1.7 3.0 0.2
2 21.0 3.5 3.0 0.2
.. ... ... ... ...
241 22.7 2.0 2.0 0.1
242 17.8 1.8 2.0 0.1
243 18.8 3.0 2.0 0.2
[244 rows x 4 columns]# element-wise, Series method
tips["tip"].map(my_format)0 1.0
1 1.7
2 3.5
...
241 2.0
242 1.8
243 3.0
Name: tip, Length: 244, dtype: objectdef peak_to_peak(arr):
return arr.max() - arr.min()# column-wise operation
tips_num.apply(peak_to_peak)total_bill 47.74
tip 9.00
size 5.00
tip_pct 0.67
dtype: float64# row-wise operation
tips_num.apply(peak_to_peak, axis="columns")0 16.93
1 10.18
2 20.84
...
241 22.58
242 17.72
243 18.62
Length: 244, dtype: float64def f2(x):
return pd.Series([x.min(), x.max()], index=["min", "max"])# apply에 패스되는 함수는 scalar 값이 아닌 Series를 반환해도 됨
tips_num.apply(f2) total_bill tip size tip_pct
min 3.07 1.00 1 0.04
max 50.81 10.00 6 0.71# Series Groupby object의 경우
tips.groupby("time")["tip"].apply(f2)time
Lunch min 1.25
max 6.70
Dinner min 1.00
max 10.00
Name: tip, dtype: float64# DataFrame GroupBy object의 경우
def f3(g):
x = g["tip"]
return pd.Series([x.min(), x.max()], index=["min", "max"])
tips.groupby("time").apply(f3) min max
time
Lunch 1.25 6.70
Dinner 1.00 10.00