Load Packages
# numerical calculation & data frames
import numpy as np
import pandas as pd
# visualization
import matplotlib.pyplot as plt
import seaborn as sns
import seaborn.objects as so
# statistics
import statsmodels.api as smMixed
# numerical calculation & data frames
import numpy as np
import pandas as pd
# visualization
import matplotlib.pyplot as plt
import seaborn as sns
import seaborn.objects as so
# statistics
import statsmodels.api as sm# pandas options
pd.set_option("mode.copy_on_write", True)
pd.options.display.precision = 2
pd.options.display.float_format = '{:.2f}'.format # pd.reset_option('display.float_format')
pd.options.display.max_rows = 7
# Numpy options
np.set_printoptions(precision = 2, suppress=True)“billboard” in a package “tidyr”
Source: The Whitburn Project
다음 링크의 데이터는 빌보드차트에 관한 데이터입니다; 링크
date_entered)인 첫주(wk1)의 순위부터 78주(wk78)의 순위까지 기록되어 있습니다.데이터를 불러오는 여러 방식에 대해서는 교재 참고
Chpter 6. Data Loading, Storage, and File Formats in Python for Data Analysis by Wes McKinney
billboard = pd.read_csv("data/billboard.csv")
billboard.head(5) artist track date_entered wk1 wk2 wk3 wk4
0 2 Pac Baby Don't Cry (Keep... 2000-02-26 87 82.00 72.00 77.00 \
1 2Ge+her The Hardest Part Of ... 2000-09-02 91 87.00 92.00 NaN
2 3 Doors Down Kryptonite 2000-04-08 81 70.00 68.00 67.00
3 3 Doors Down Loser 2000-10-21 76 76.00 72.00 69.00
4 504 Boyz Wobble Wobble 2000-04-15 57 34.00 25.00 17.00
wk5 wk6 wk7 ... wk67 wk68 wk69 wk70 wk71 wk72 wk73 wk74
0 87.00 94.00 99.00 ... NaN NaN NaN NaN NaN NaN NaN NaN \
1 NaN NaN NaN ... NaN NaN NaN NaN NaN NaN NaN NaN
2 66.00 57.00 54.00 ... NaN NaN NaN NaN NaN NaN NaN NaN
3 67.00 65.00 55.00 ... NaN NaN NaN NaN NaN NaN NaN NaN
4 17.00 31.00 36.00 ... NaN NaN NaN NaN NaN NaN NaN NaN
wk75 wk76
0 NaN NaN
1 NaN NaN
2 NaN NaN
3 NaN NaN
4 NaN NaN
[5 rows x 79 columns]총 몇 명의 가수(artist)가 차트에 있으며, 가수별로 몇 곡(track)이 차트에 들어있는지 알아보세요. (동명이인은 없다고 가정하고)
곡명은 같지만, 가수가 다른 곡이 있는지 알아보고, 서로 다른 노래가 차트에 몇 개나 있는지 알아보세요.
살펴보았다면, 이후 grouping시 artist와 track을 함께 사용해야함을 이해했을 겁니다.
이 데이터를 주(week)에 대해서 아래처럼 long format으로 바꿉니다.
wk column에 wk1부터 missing이 없는 wk*까지 숫자로 표현되고,rank column에는 해당하는 week의 순위가 나타납니다.melt()를 이용하고, (id_vars=["artist", "track", "date_entered"]).str.replace()와 .astype("int64")를 사용해야 할 수 있습니다..dropna(subset="rank", inplace=True)를 사용하여 rank column의 missing을 처리하세요.billboard_long 변수에 할당하여 이후 문제를 이어가세요.
billboard_long artist track date_entered wk rank
0 2 Pac Baby Don't Cry (Keep... 2000-02-26 1 87.00
317 2 Pac Baby Don't Cry (Keep... 2000-02-26 2 82.00
634 2 Pac Baby Don't Cry (Keep... 2000-02-26 3 72.00
... ... ... ... .. ...
11728 matchbox twenty Bent 2000-04-29 37 38.00
12045 matchbox twenty Bent 2000-04-29 38 38.00
12362 matchbox twenty Bent 2000-04-29 39 48.00
[5307 rows x 5 columns].size()를 이용해 구한 후query()를 이용해 50주 이상으로 필터링artist와 track순으로 정렬되어 있는지 확인해 주세요!(
billboard_long.groupby(...)
.size()
...
.query(...)
) billboard_long)를 merge()를 이용해 추린 후, 50주 이상 머문 곡으로 필터링하세요.
seaborn.objects를 이용해 대략 다음과 같이 주에 따른 순위의 변화를 그려보세요. 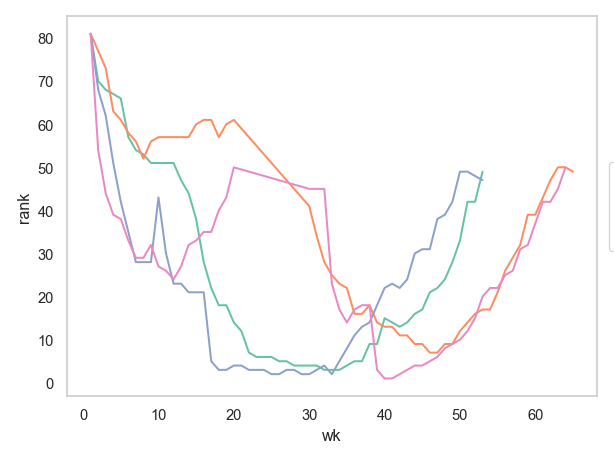
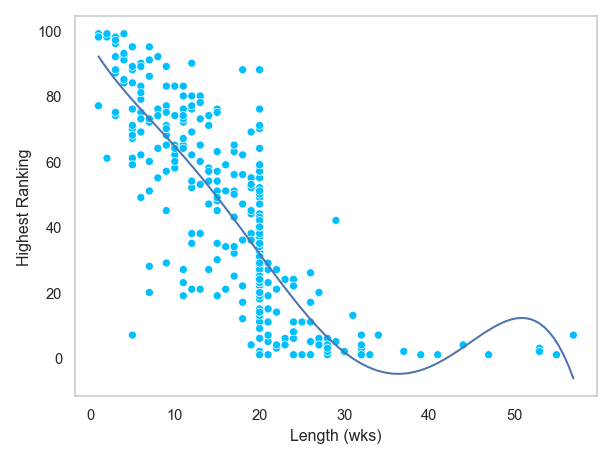
.reset_index(name=" ") 이용min()을 이용해 DataFrame으로 구한 후merge()를 이용해 합친 후seaborn.objects를 이용해 머문 기간에 따른 최상위 순위에 대한 관계를 아래와 같이 scatterplot으로 살펴보세요.
함수를 만들고; min()과 argmin()이 필요할 수 있음
apply()로 그 함수를 적용하여 구해보세요.
# artist track wk rank
# 0 Aaliyah Try Again 1 59.00
# 1 Aaliyah Try Again 14 1.00
# 2 Aguilera, Christina Come On Over Baby (A... 1 57.00
# 3 Aguilera, Christina Come On Over Baby (A... 11 1.00
# 4 Aguilera, Christina What A Girl Wants 1 71.00
# 5 Aguilera, Christina What A Girl Wants 8 1.00
...7번을 구하지 못한 경우, 다음 파일을 받아 이용하세요.
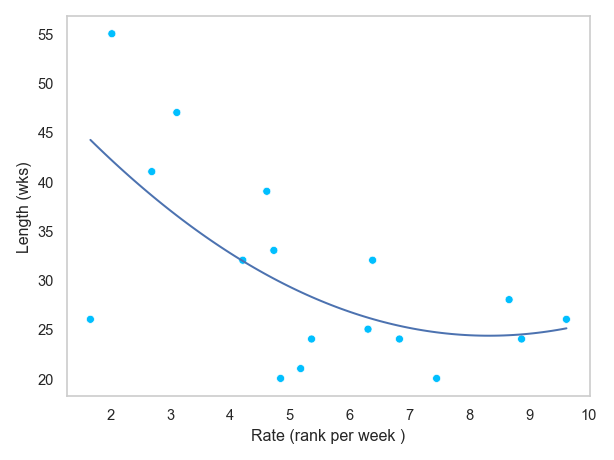
즉, 차트 진입시의 순위 정보와, 1위가 된 week의 정보만을 취해, 그 비율(rate)를 구하면, 얼마나 빠르게 1위가 되었는지 알 수 있습니다.
# artist track wk rank rate
# 0 Aaliyah Try Again 14 59.00 4.21
# 1 Aguilera, Christina Come On Over Baby (A... 11 57.00 5.18
# 2 Aguilera, Christina What A Girl Wants 8 71.00 8.88
# 3 Carey, Mariah Thank God I Found Yo... 11 82.00 7.45
# 4 Creed With Arms Wide Open 27 84.00 3.11
# 5 Destiny's Child Independent Women Pa... 9 78.00 8.67
# ...마지막으로, seaborn.objects를 이용해 다음과 같이 시각화해보세요.