# numerical calculation & data framesimport numpy as npimport pandas as pd# visualizationimport matplotlib.pyplot as pltimport seaborn as snsimport seaborn.objects as soimport plotly.express as px# statisticsimport statsmodels.api as sm
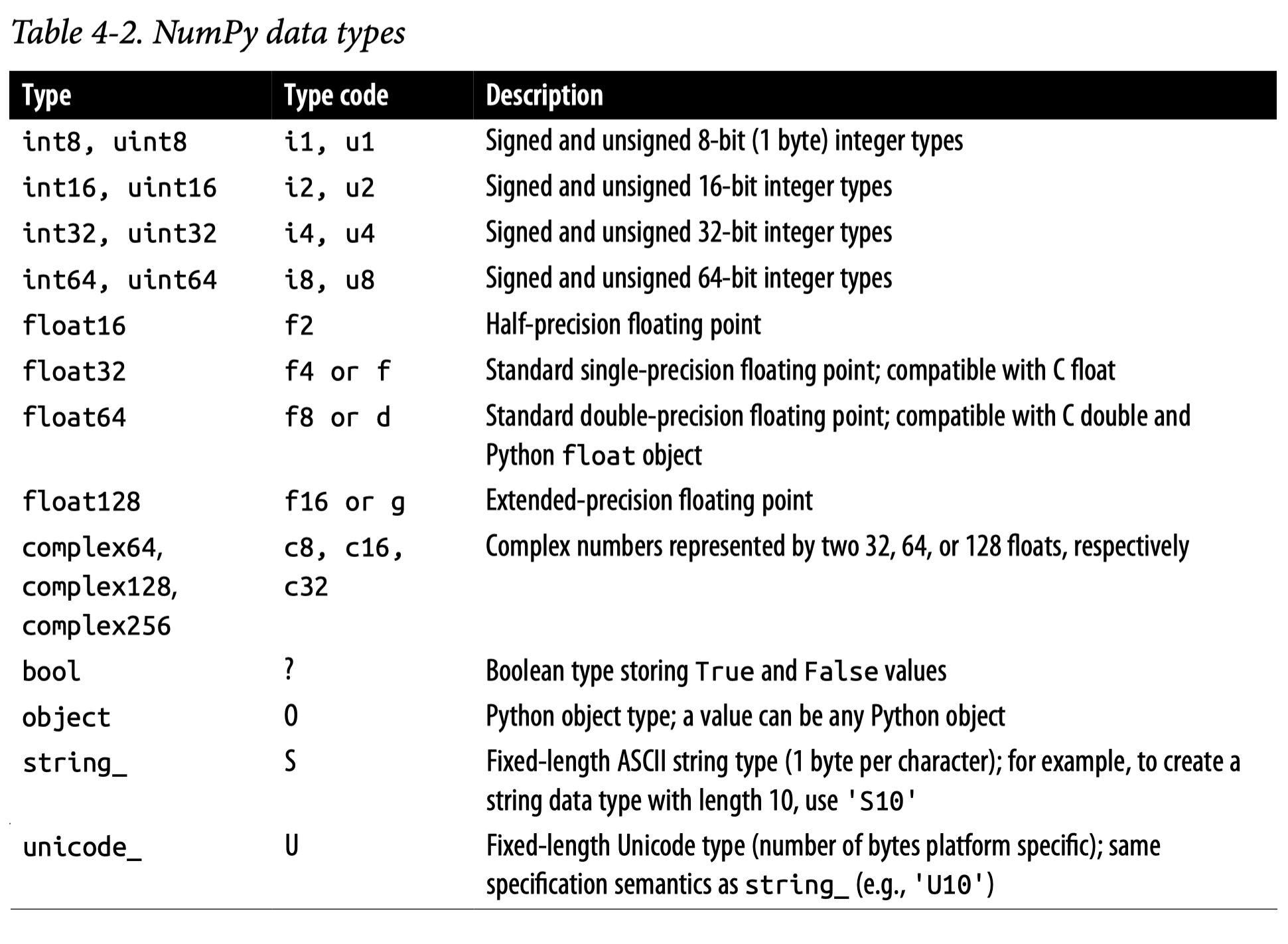
Python 언어는 수치 계산을 위해 디자인되지 않았기 때문에, 데이터 분석에 대한 효율적이고 빠른 계산이 요구되면서 C/C++이라는 언어로 구현된 NumPy (Numerical Python)가 탄생하였고, Python 생태계 안에 통합되었음. 기본적으로 Python 언어 안에 새로운 언어라고 볼 수 있음. 데이터 사이언스에서의 대부분의 계산은 NumPy의 ndarray (n-dimensioal array)와 수학적 operator들을 통해 계산됨.
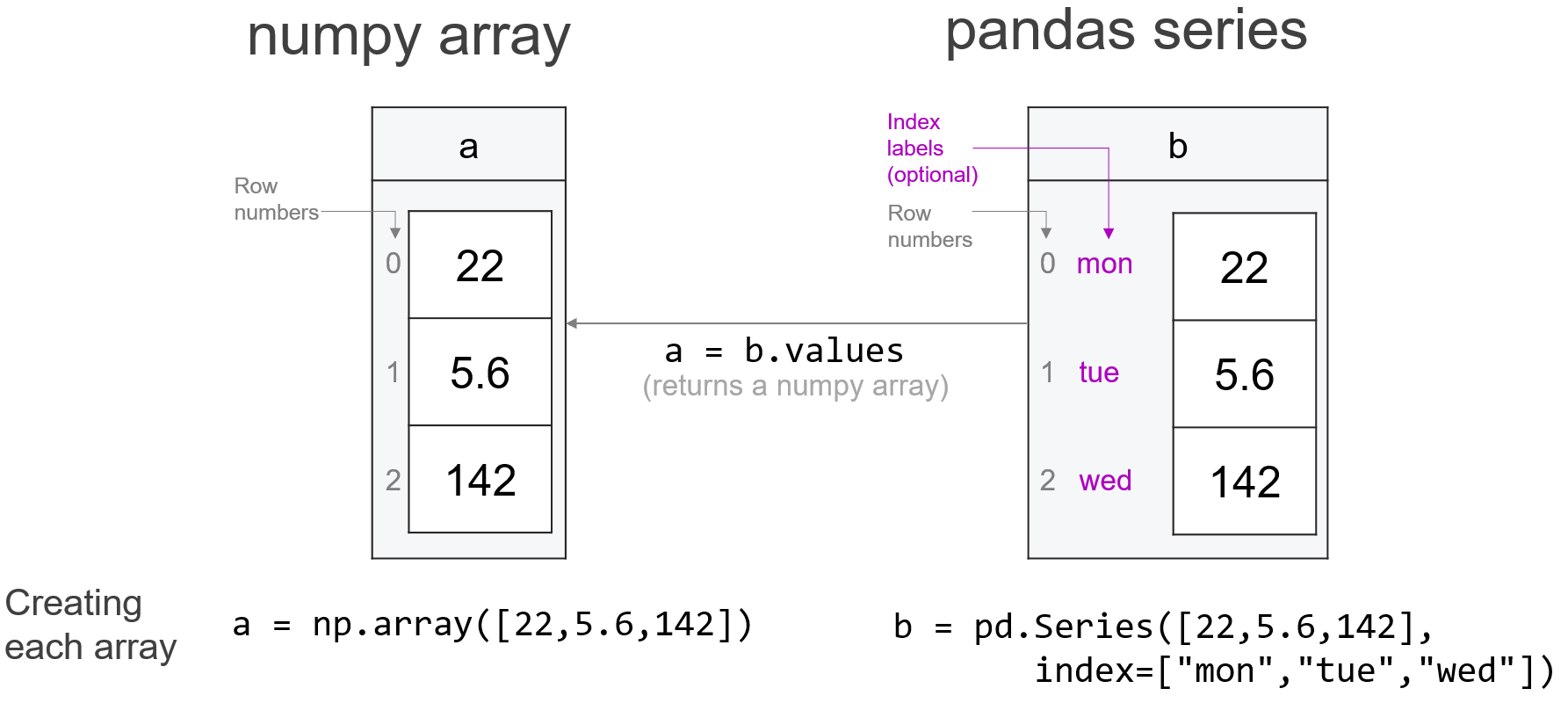
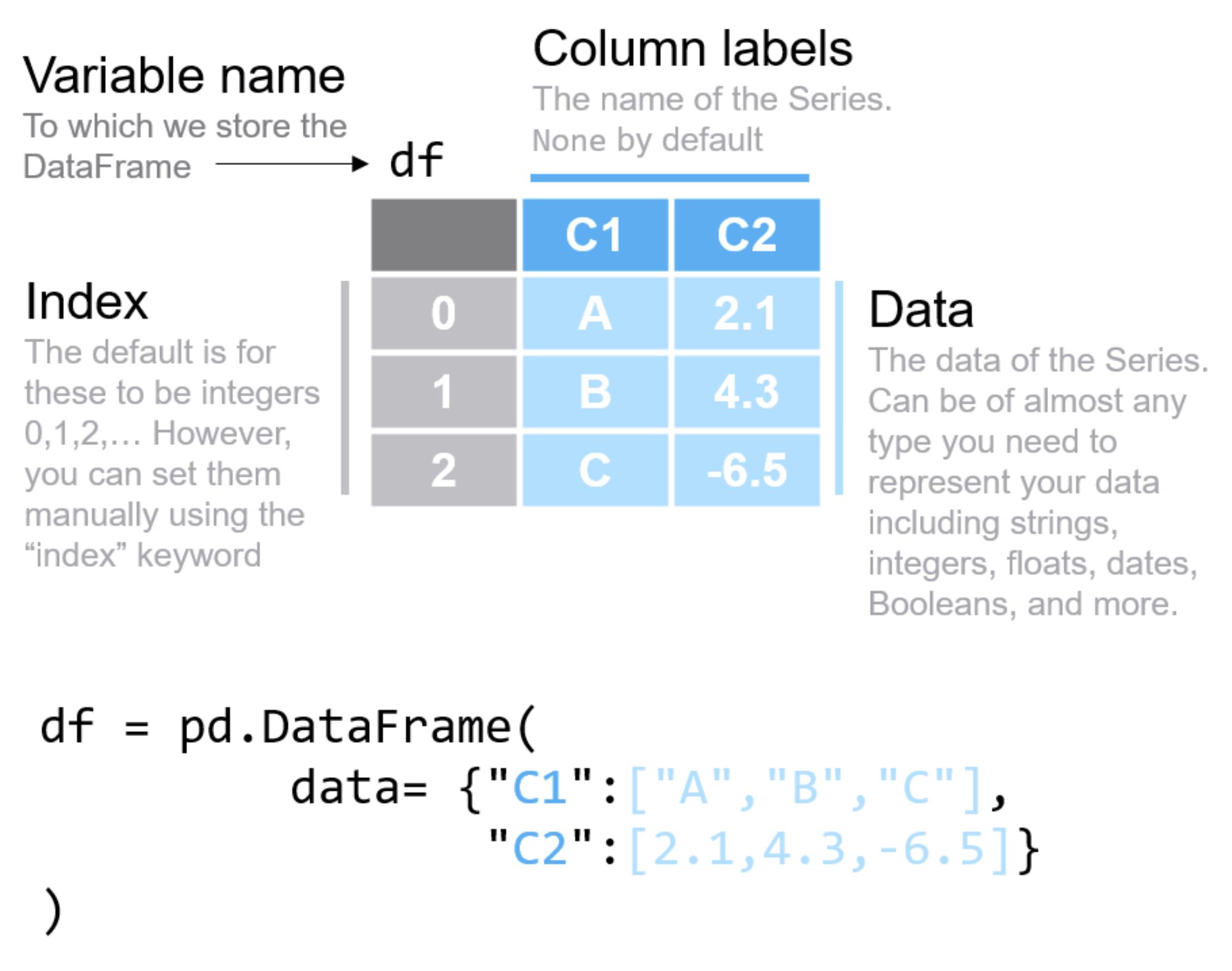
데이터 사이언스가 발전함에 따라 단일한 floating-point number들을 성분으로하는 array들의 계산에서 벗어나 칼럼별로 다른 데이터 타입(string, integer, object..)을 포함하는 tabular형태의 데이터를 효율적으로 처리해야 할 필요성이 나타났고, 이를 다룰 수 있는 새로운 언어를 NumPy 위에 개발한 것이 pandas임. 이는 기본적으로 Wes Mckinney에 의해 독자적으로 개발이 시작되었으며, 디자인적으로 불만족스러운 점이 지적되고는 있으나 데이터 사이언스의 기본적인 언어가 되었음.
NumPy와 pandas에 대한 자세한 내용은 Python for Data Analysis by Wes MacKinney 참고
특히, NumPy는 Ch.4 & appendices
NumPy
수학적 symbolic 연산에 대한 구현이라고 볼 수 있으며,
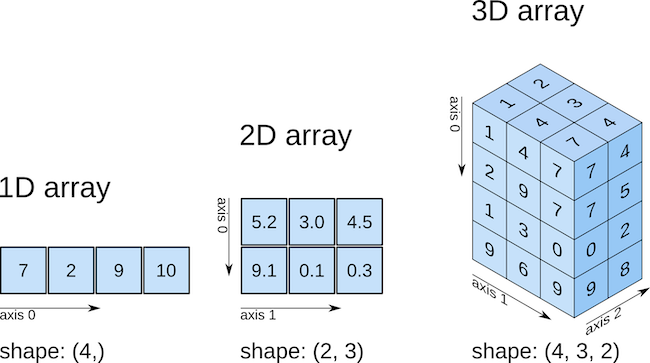
행렬(matrix) 또는 벡터(vector)를 ndarray (n-dimensional array)이라는 이름으로 구현함.
NumPy의 ndarray들이 연산되는 방식과 동일하게 series나 DataFrame들의 연산 가능함
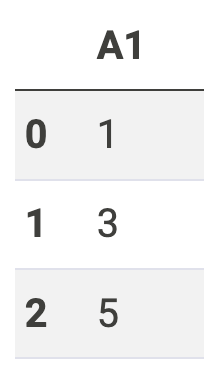
df +2* df
A1 A2
0 3 6
1 9 12
2 15 18
np.log(df)
A1 A2
0 0.00 0.69
1 1.10 1.39
2 1.61 1.79
사실 연산은 index를 align해서 시행됨
number one two three
state
Ohio 0 1 2
Colorado 3 4 5
number one two three
state
Ohio 0 2 4
Floria 6 8 10
frame1 + frame2
number one two three
state
Colorado NaN NaN NaN
Floria NaN NaN NaN
Ohio 0.00 3.00 6.00
(참고) Mixed Data Type
s = pd.Series([1, 2, "3"])
s.dtype
dtype('O')
s + s
0 2
1 4
2 33
dtype: object
s_int = s.astype("int")s_int + s_int
0 2
1 4
2 6
dtype: int64
s2 = pd.Series([1, 2, 3.1])s2.dtype
dtype('float64')
s2.astype("int")
0 1
1 2
2 3
dtype: int64
Missing
NaN, NA, None
pandas에서는 missing을 명명하는데 R의 컨벤션을 따라 NA (not available)라 부름.
대부분의 경우에서 NumPy object NaN(np.nan)을 NA을 나타내는데 사용됨. np.nan은 실제로 floating-point의 특정 값으로 float64 데이터 타입임. Integer 또는 string type에서 약간 이상하게 작동될 수 있음.
Python object인 None은 pandas에서 NA로 인식함.
현재 NA라는 새로운 pandas object 실험중임
NA의 handling에 대해서는 교재 참고 .dropna(), .fillna(), .isna(), .notna()
Mckinney’s: 7.1 Handling Missing Data,
Mollin’s: 3.5 Handling duplicate, missing, or invalid data